MindGames (NeurIPS 2025 Competition)
by Leon Guertler & Bobby Cheng
MindGames is a a NeurIPS25 competition for text-based games that Bobby and I helped organize. Since we are obviously not allowed to participated, we wanted to write this short blog explaining how we would use UnstableBaselines, to train and submit a model to the competition (optimally giving you a small edge over your competition).
MindGames has two main trackes focused on Theory of Mind (ToM) (one for Secretmafia-v0 and one for Codenames-v0, ColonelBlotto-v0 and ThreePlayerIPD-v0). In our experience, the biggest challange is training small (i.e. <8B) models on games with natural language action space (i.e. very conversational games), since the full actions will be part of the next players osbervation. Thus, in this mini-blog we will focus on track two, since ThreePlayerIPD-v0 is the only such environment in it.
Since we have also been training on these games for a couple of months, we created versions of them where the observations are structured in a training-friendly manner (you can access them by using the suffic -train; i.e. Codenames-v0 -> Codenames-v0-train). This will work both for offline training and your online submission. Note that this won’t change the environment itself, but rather how the observations are structured and presented to the model.
First things first, we need to decide on a model and build the training script. In Spiral we used the Qwen3-4B-Base, which worked very well; since the size limit for the small model track in this competition is 8B, here we will use the slightly larger Qwen3-8B-Base.
As for the training script, since 8B is rather big, we will use UnstableBaselines, which uses LoRA and activation checkpointing, thus 48GB of vRam should be enough (for this blog we will use our 3x RTX6000 ada machine; if you only have access to 24gb of vRam you will likely have to go with the 4B version of the model).
You can install UnstableBaselines via pip install unstable-rl (this will also install TextArena and anything else you need).
Imports
Now we can set up the training script. I will first explain the components one by one, and then show the full script at the bottom.
First we need to import all relevant packages; specifically, time, ray, unstable (the package name for UnstableBaselines) and the reward transformations from UnstableBaselines.
import ray, unstable, time
import unstable.reward_transformations as retra
Constants & Configs
Now we can initialize constants and build the two necessary configuration configs (namely, the lora_config, specifying the lora size and which layers to apply it to, and the vllm_config, specifying our generation hyperparameters):
MODEL_NAME = "qwen/Qwen3-8B-Base"
MAX_GENERATION_LENGTH = 4096
MAX_TRAIN_SEQ_LEN = 3000 # if you are running out of vRam, you can decrease this.
lora_config = {
"lora_rank": 32, "lora_alpha": 32, "lora_dropout": 0.0,
"target_modules": ["q_proj","k_proj","v_proj","o_proj","gate_proj", "up_proj","down_proj"]
}
vllm_config = {
"model_name": MODEL_NAME, "temperature": 0.6, "max_tokens": MAX_GENERATION_LENGTH,
"max_parallel_seq": 128, "max_loras": 8, "lora_config": lora_config,
"max_model_len": 8192
}
Init Ray & Specify Environments
With everything imported and specified, we can now initialize ray and start building the relevant modules from unstable.
ray.init(namespace="unstable")
# initialize environment scheduler
env_sampler = unstable.samplers.env_samplers.UniformRandomEnvSampler(
train_env_specs=[
unstable.TrainEnvSpec(
env_id="Codenames-v0-train",
num_players=4,
num_actors=4,
prompt_template="qwen3-zs"
),
unstable.TrainEnvSpec(
env_id="ColonelBlotto-v0-train",
num_players=2,
num_actors=2,
prompt_template="qwen3-zs"
),
unstable.TrainEnvSpec(
env_id="ThreePlayerIPD-v0-train",
num_players=3,
num_actors=3,
prompt_template="qwen3-zs"
),
],
eval_env_specs=[
unstable.EvalEnvSpec(
env_id="Codenames-v0-train",
num_players=4,
prompt_template="qwen3-zs"
),
unstable.EvalEnvSpec(
env_id="ColonelBlotto-v0-train",
num_players=2,
prompt_template="qwen3-zs"
),
unstable.EvalEnvSpec(
env_id="ThreePlayerIPD-v0-train",
num_players=3,
prompt_template="qwen3-zs"
),
])
The TrainEnvSpec expects the env_id (same as in TextArena), the num_players of the environment, the num_actors we want to use to collect data (i.e. if num_players==num_actors we will use mirror self-play with no opponent sampling) and the prompt_template used to process the observations. The EvalEnvSpec will use fixed_opponent=google/gemini-2.0-flash-lite-001 as the default fixed opponent. Make sure to export your OpenRouter api key via export OPENROUTER_API_KEY="YOUR_KEY" before running the script.
Tracker & Model Registry
Next up we will build the Tracker and ModelRegistry. The former is responsible for WandB logging as well as local path handling. The latter will keep track of all checkpoints and fixed opponents for model sampling.
tracker = unstable.Tracker.options(name="Tracker").remote(
run_name=f"Test-{MODEL_NAME.split('/')[-1]}-{env_sampler.env_list()}-{int(time.time())}",
wandb_project="UnstableBaselines"
)
model_registry = unstable.ModelRegistry.options(name="ModelRegistry").remote(tracker=tracker)
ray.get(model_registry.add_checkpoint.remote(uid="base", path=None, iteration=0))
We will add the base model (i.e. lora_path = None) to the model registry as well.
ModelSampler & GameScheduler
Finally we can initialize our ModelSampler (since we are doing mirror self-play we will only use the base sampler here (i.e. where the sample_opponent function is not implemented), using different opponent sampling methods to boost performance is a great starting off point btw) and GameScheduler. The GameScheduler is responsible for scheduling environments and models. In this example we will just randomly pick an environment for each game and don’t need to sample opponents (since we are doing mirror self-player); but this is something worth playing with to boost performance.
model_sampler = unstable.samplers.model_samplers.BaseModelSampler(
model_registry=model_registry
)
game_scheduler = unstable.GameScheduler.options(name="GameScheduler").remote(
model_sampler=model_sampler,
env_sampler=env_sampler,
logging_dir=ray.get(tracker.get_log_dir.remote())
)
StepBuffer
In this code example we will use REINFORCE as the learning algorithm. Thus it is enough to keep track of individual Steps (i.e. obs, action, reward triplets). However, if you want to use A2C, for example, you’ll need to switch to the TrajectoryBuffer.
step_buffer = unstable.StepBuffer.options(name="Buffer").remote(
max_buffer_size=768,
tracker=tracker,
final_reward_transformation=retra.ComposeFinalRewardTransforms([
retra.RoleAdvantageByEnvFormatter()
]),
step_reward_transformation=retra.ComposeStepRewardTransforms([
retra.RewardForFormat(1.5),
retra.PenaltyForInvalidMove(1.0, -1.0)
]),
sampling_reward_transformation=retra.ComposeSamplingRewardTransforms([
retra.NormalizeRewardsByEnv(True)
]),
)
The max_buffer_size specifies how many Steps at most will be held in the buffer. If we exceed this amount, the default sub-sampling strategy is to randomly delete old Steps. Additionally we are passing the Tracker object and specify the different reward transformations:
- FinalRewardTransforms Will be applied first and is responsible for any transformation on the environment rewards. In this case we wil track the ema role-based reward and subtract it from the final reward. This is very important for games that have strong role biases (i.e. TicTacToe).
- StepRewardTransforms When the trajectory is split into individual steps, these transformations are applied. In this case we will reward the correct format (i.e. \boxed{}) and valid moves.
- SamplingRewardTransforms Lastly, when pulling the next batch for training, the sampling rewards are applied. In this case just a standard normal transformation.
Collector
Bringing it all together, we build the Collector which is responsible for running a fixed number of games in parallel, and pushing fhinished episodes to the StepBuffer:
collector = unstable.Collector.options(name="Collector").remote(
vllm_config=vllm_config,
tracker=tracker,
buffer=step_buffer,
game_scheduler=game_scheduler
)
Learner
As previously mentioned, in this example we will use the REINFORCE algorithm as our learner.
learner = unstable.REINFORCELearner.options(num_gpus=1, name="Learner").remote(
model_name=MODEL_NAME,
lora_cfg=lora_config,
batch_size=384,
mini_batch_size=1,
learning_rate=1e-5,
grad_clip=0.2,
buffer=step_buffer,
tracker=tracker,
model_registry=model_registry,
activation_checkpointing=True,
gradient_checkpointing=True,
use_trainer_cache=False
)
ray.get(learner.initialize_algorithm.remote(
max_train_len=MAX_TRAIN_SEQ_LEN,
max_generation_len=MAX_GENERATION_LENGTH
))
To save vRam, we will use mini-batch-size 1. The other important vRam saving parameter is the activation_checkpointing. It will slow the code down by 20-30%, but also reduced vRAM requirements by almost 50%. If you are gpu-rich, you can disable it.
For the REINFORCELearner, we also need to set the max_train_len and max_generation_length. The latter is used for the Dr. GRPO trick. I.e.:
seq_logp = (tok_logp * mask).sum(1) / self.max_generation_len
The max_train_len is used to truncate the number of tokens trained on from sequences that are too long without impacting the rewards. In practice the generation length of models usually spikes initally and then decreases. This parameter will allow you to train larger models w/o crashing the run and usually does not affect convergence.
Putting it all together
The full script to run will be:
import ray, unstable, time
import unstable.reward_transformations as retra
MODEL_NAME = "qwen/Qwen3-8B-Base"
MAX_GENERATION_LENGTH = 4096
MAX_TRAIN_SEQ_LEN = 3000 # if you are running out of vRam, you can decrease this.
lora_config = {
"lora_rank": 32, "lora_alpha": 32, "lora_dropout": 0.0,
"target_modules": ["q_proj","k_proj","v_proj","o_proj","gate_proj", "up_proj","down_proj"]
}
vllm_config = {
"model_name": MODEL_NAME, "temperature": 0.6, "max_tokens": MAX_GENERATION_LENGTH,
"max_parallel_seq": 128, "max_loras": 8, "lora_config": lora_config,
"max_model_len": 8192
}
ray.init(namespace="unstable") # the namespace is mostly important for the terminal_interface.py script (which loads the modules from the "unstable" namespace)
# initialize environment scheduler
env_sampler = unstable.samplers.env_samplers.UniformRandomEnvSampler(
train_env_specs=[
unstable.TrainEnvSpec(
env_id="Codenames-v0-train",
num_players=4,
num_actors=4,
prompt_template="qwen3-zs"
),
unstable.TrainEnvSpec(
env_id="ColonelBlotto-v0-train",
num_players=2,
num_actors=2,
prompt_template="qwen3-zs"
),
unstable.TrainEnvSpec(
env_id="ThreePlayerIPD-v0-train",
num_players=3,
num_actors=3,
prompt_template="qwen3-zs"
),
],
eval_env_specs=[
unstable.EvalEnvSpec(
env_id="Codenames-v0-train",
num_players=4,
prompt_template="qwen3-zs"
),
unstable.EvalEnvSpec(
env_id="ColonelBlotto-v0-train",
num_players=2,
prompt_template="qwen3-zs"
),
unstable.EvalEnvSpec(
env_id="ThreePlayerIPD-v0-train",
num_players=3,
prompt_template="qwen3-zs"
),
])
tracker = unstable.Tracker.options(name="Tracker").remote(
run_name=f"Test-{MODEL_NAME.split('/')[-1]}-{env_sampler.env_list()}-{int(time.time())}",
wandb_project="UnstableBaselines"
)
model_registry = unstable.ModelRegistry.options(name="ModelRegistry").remote(tracker=tracker)
ray.get(model_registry.add_checkpoint.remote(uid="base", path=None, iteration=0))
model_sampler = unstable.samplers.model_samplers.BaseModelSampler(
model_registry=model_registry
)
game_scheduler = unstable.GameScheduler.options(name="GameScheduler").remote(
model_sampler=model_sampler,
env_sampler=env_sampler,
logging_dir=ray.get(tracker.get_log_dir.remote())
)
step_buffer = unstable.StepBuffer.options(name="Buffer").remote(
max_buffer_size=768,
tracker=tracker,
final_reward_transformation=retra.ComposeFinalRewardTransforms([
retra.RoleAdvantageByEnvFormatter()
]),
step_reward_transformation=retra.ComposeStepRewardTransforms([
retra.RewardForFormat(1.5),
retra.PenaltyForInvalidMove(1.0, -1.0)
]),
sampling_reward_transformation=retra.ComposeSamplingRewardTransforms([
retra.NormalizeRewardsByEnv(True)
]),
)
collector = unstable.Collector.options(name="Collector").remote(
vllm_config=vllm_config,
tracker=tracker,
buffer=step_buffer,
game_scheduler=game_scheduler
)
learner = unstable.REINFORCELearner.options(num_gpus=1, name="Learner").remote(
model_name=MODEL_NAME,
lora_cfg=lora_config,
batch_size=384,
mini_batch_size=1,
learning_rate=1e-5,
grad_clip=0.2,
buffer=step_buffer,
tracker=tracker,
model_registry=model_registry,
activation_checkpointing=True,
gradient_checkpointing=True,
use_trainer_cache=False
)
ray.get(learner.initialize_algorithm.remote(
max_train_len=MAX_TRAIN_SEQ_LEN,
max_generation_len=MAX_GENERATION_LENGTH
))
try:
collector.collect.remote(
num_train_workers=512,
num_eval_workers=16
) # if you are running out of ram, you can reduce this
ray.get(learner.train.remote(200))
finally:
ray.kill(collector, no_restart=True)
ray.shutdown()
I put the code into a script called mind_games_demo.py, so will run it via python3 mind_games_demo.py.
You can now open a new terminal on the same machine and track your training run via unstable-terminal, which will look something like this:
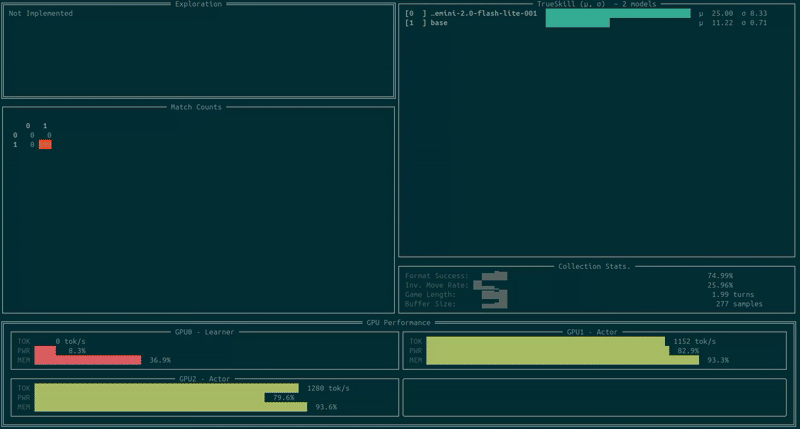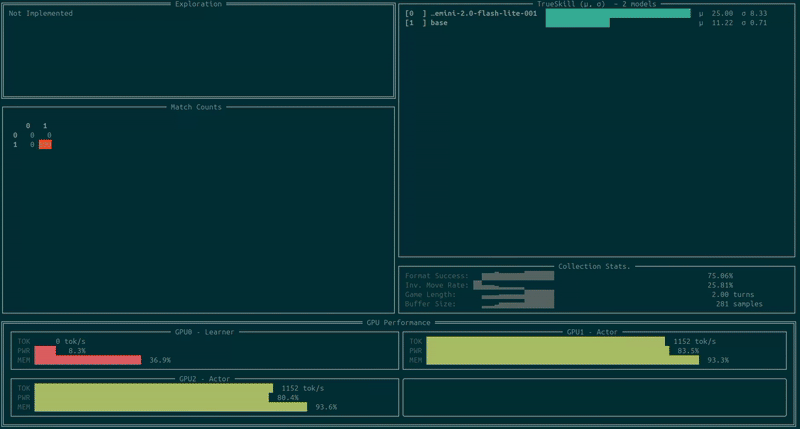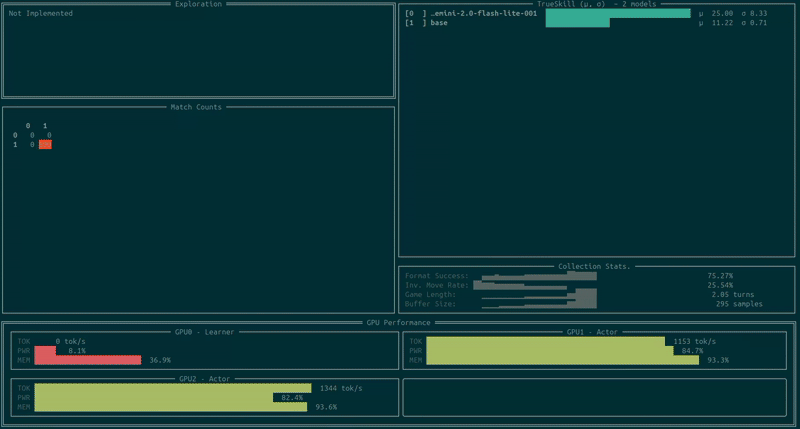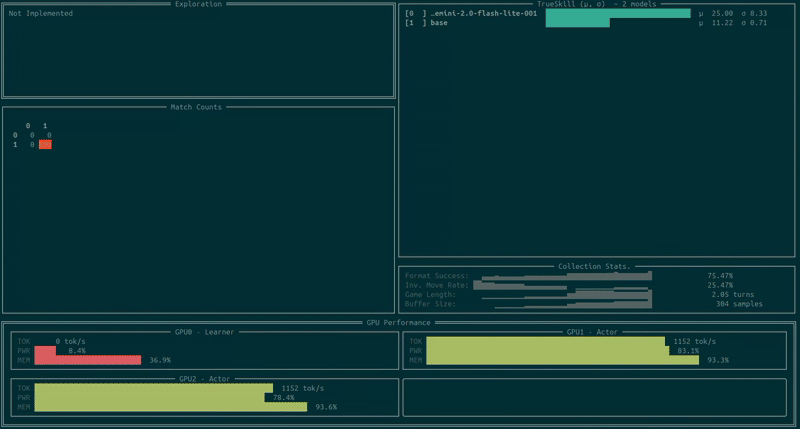
We can also track the results via Weights & Biases. Keep in mind that the eval performance on W&B should be treated as a proxy for performance as it can be slightly lagging (depending on the hardware and game length). For the above run I got the following:
Training perf.
Tbh, all of these are proxies, but when I try to read the w&b tealeafs for self-play runs, I usually first check the game length and invalid move rates. Those will be good proxies for the model learning how to play the game (although you need to keep the environment design in mind, more on that in a bit):
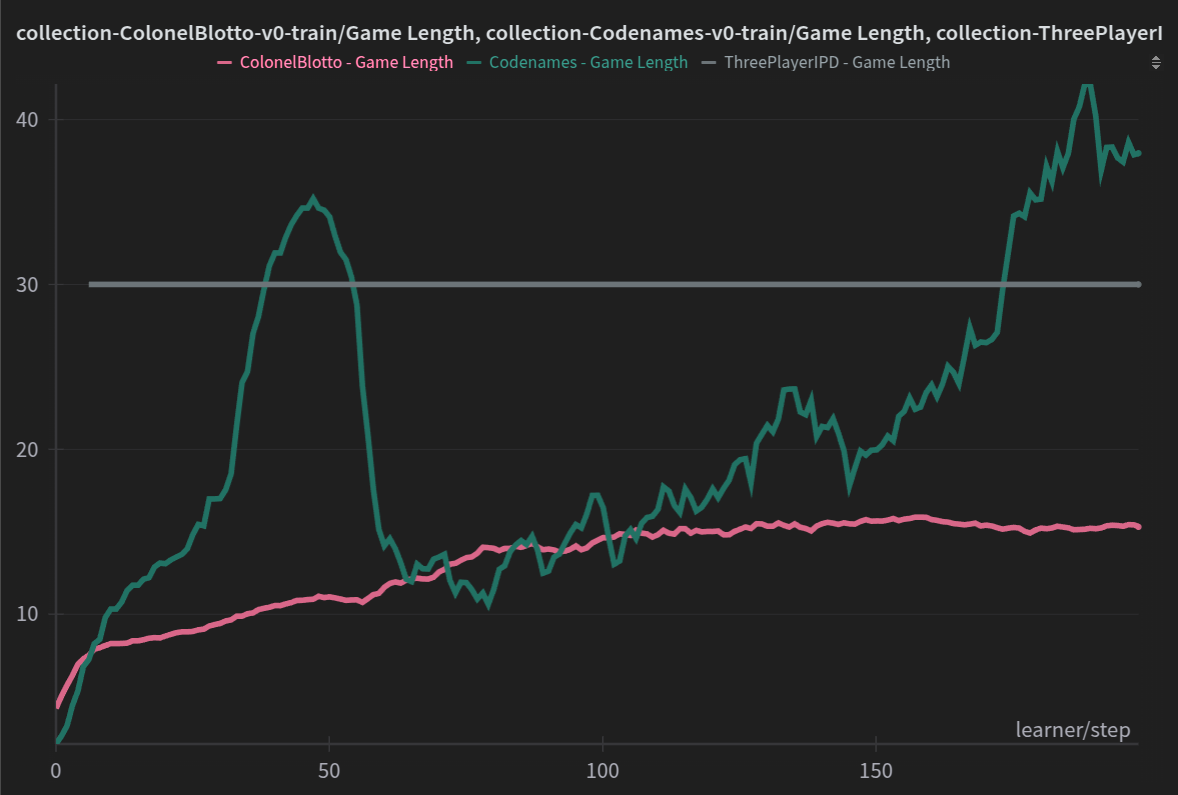
As you can see, the game length (and change thereof) differs significantly for the different envs. ThreePlayerIPD does not really have invalid moves (which actually makes training a bit harder), so the runs always last 30 turns. Codenames does have invalid moves (the turn will be skipped) and you can see the models initially learning to descibe words well enough that the game length goes down to 12 or so turns, before coming back up (without looking at the games it is hard to say why this is happening). ColonelBlotto, the easiest out of the three games looks great. Game length is stably increasing as expected (since here invalid moves will actually end the game). Again, I do want to highlight, this is essentially tealeaf reading, AI is alchemy, not a science and at best you can build your intuition for how to interpret these things, there is not 100% correct answer.
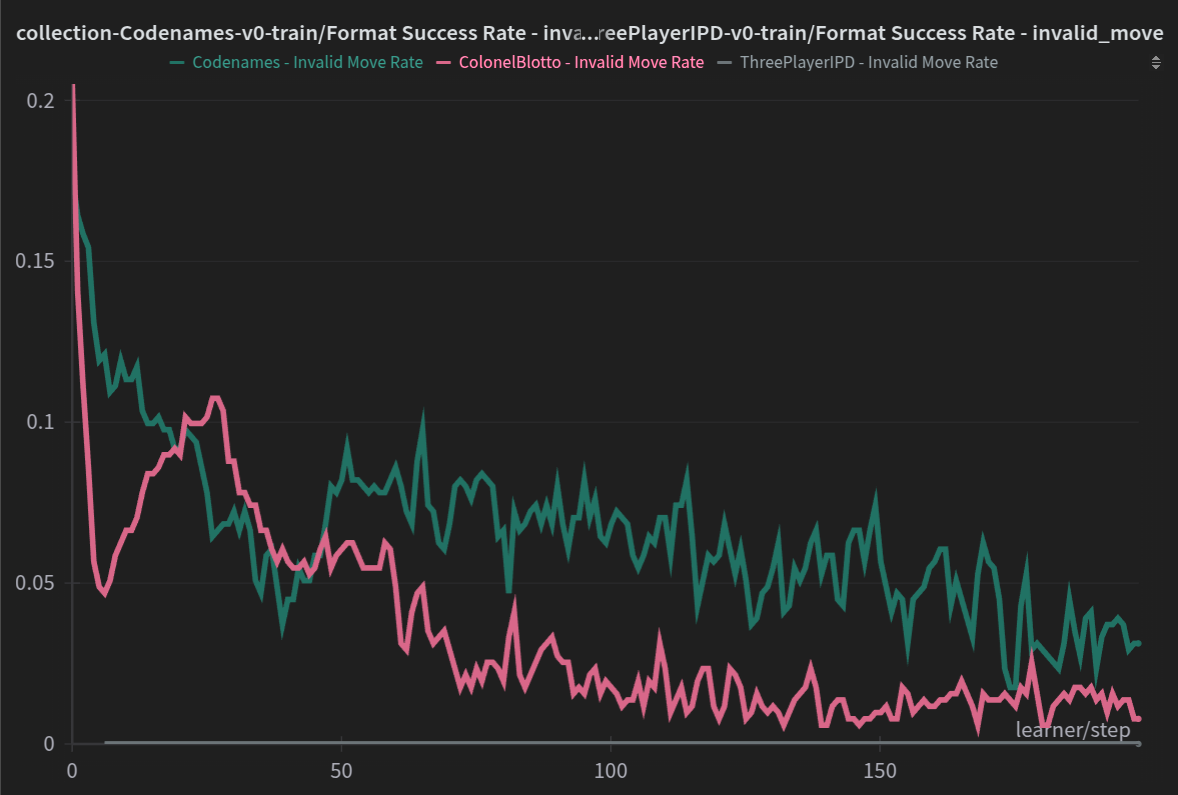
Another good proxy (depending on the environment) is the invalid move rate of the model. As you can see, it’s going down stably, which is a great sign.
Evaluation perf.
Given that the training performance mostly looks good, we can now move on to checking the eval games we ran during training. Here we will simply check the win-rate against our fixed opponent:
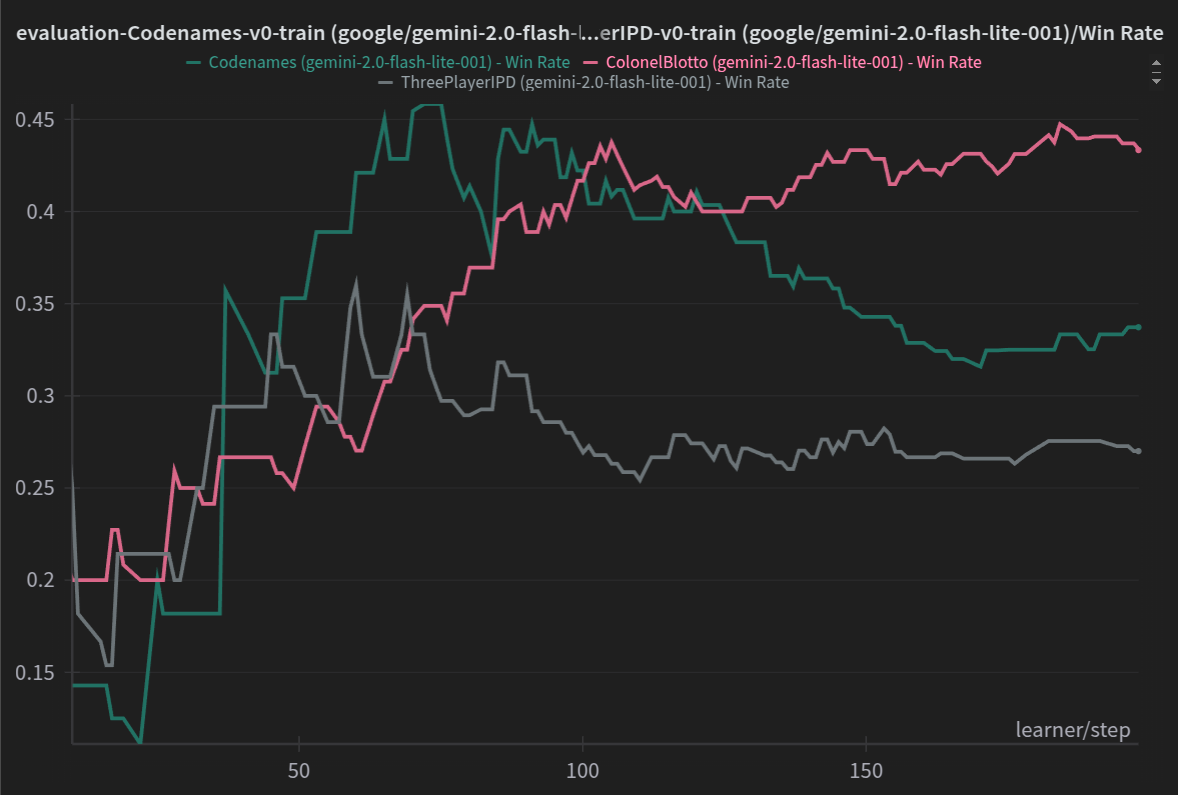
There are certainly significant win-rate gains during training, although Codenames seems to diverge from it’s 45% peak towards the end of training. ColonelBlotto looks pretty much textbook and how we would expect it to. These results indicate that the model certainly learned something and managed to more than double it’s eval performance on most envs.
Now we can move to evaluating this checkpoint offline against a stronger <8B model, and subsequently online.
Setting up Offline & Online Evaluation
Before running any eval, we first need to figure out a good way of loading and running the model we just trained. Generally speaking there are a lot of ways to do this, but my favourite one is to merge the lora weights into the model and uplod the merged model to HF. Here is the script I usually use:
import argparse
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
def parse_args():
parser = argparse.ArgumentParser(description="Merge LoRA weights into a base model and push to HuggingFace")
parser.add_argument("--base-model", type=str, required=True, help="HuggingFace path to the base model",)
parser.add_argument("--lora-path", type=str, required=True, help="Path to the LoRA adapter weights")
parser.add_argument("--target-path", type=str, required=True, help="HuggingFace path to save the merged model",)
parser.add_argument("--device", type=str, default="cpu", help="Device to use for merging (cuda, cpu)",)
parser.add_argument("--dtype", type=str, default="float16", choices=["float16", "bfloat16", "float32"], help="Data type for model loading and saving",)
return parser.parse_args()
def main():
args = parse_args()
print(f"Loading base model from {args.base_model}")
# Load base model
model = AutoModelForCausalLM.from_pretrained(
args.base_model,
device_map="cpu",
trust_remote_code=True
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(
args.base_model,
trust_remote_code=True
)
print(f"Loading LoRA adapter from {args.lora_path}")
# Load and merge LoRA weights
model = PeftModel.from_pretrained(model, args.lora_path)
print("Merging LoRA weights with base model")
model = model.merge_and_unload()
print(f"Saving merged model to {args.target_path}")
# Save the merged model
model.push_to_hub(args.target_path)
tokenizer.push_to_hub(args.target_path)
print("Merge and save completed successfully!")
if __name__ == "__main__":
main()
All checkpoints from our training run can be found in the outputs folder (sorted by date and time). Since we ran the training for 200 iterations, the final checkpoint will be iteration 199. Here is how you can call the above merging script (I stored it as merge_model.py):
python3 merge_model.py --base-model "qwen/Qwen3-8B-Base" --lora-path "YOUR_LORA_CKPT_FOLDER" --target-path "YOUR_HF_TARGET_NAME"
In my case:
python3 merge_model.py --base-model "qwen/Qwen3-8B-Base" --lora-path "/home/guertlerlo/Desktop/MindGames/outputs/2025-07-18/13-35-10/Test-Qwen3-8B-Base-Codenames-v0-train,ColonelBlotto-v0-train,ThreePlayerIPD-v0-train-1752816906/checkpoints/iteration-199" --target-path "LeonGuertler/MindGamesDemoRun"
This will run for maybe 10min or so depending on your hardware and internet speed. Once done, we can use the HFLocalAgent we provide as part of TextArena to load the model into a game-playing format. But I am paranoid, so usually prefer to build things from scratch to make sure it’s working as intended. So, Let’s build our own game-playing (TextArena compatible) class for the checkpoint we just trained.
The key components are: loading the model, formatting the inputs, extracting the actions and populating the __call__ function. Here is what I wrote:
import re, torch
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
class UnstableAgent:
def __init__(self, hf_name: str):
# load the model and tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(hf_name)
self.model = AutoModelForCausalLM.from_pretrained(hf_name)
self.model.to("cuda" if torch.cuda.is_available() else "cpu")
# we will just copy the exact fromatting and extraction
# functions from UnstableBaselines
def _format_prompt(self, obs: str) -> str:
return (
f"<|im_start|>user\nYou are playing a two-player zero-sum game. Make valid actions to win.\n"
f"Observation: {obs}\nPlease reason step by step, and put your final answer within \\boxed.<|im_end|>\n"
"<|im_start|>assistant\n"
)
def _action_extraction(self, raw_action: str) -> str:
matches = re.findall(r"\\boxed\{(.*?)\}", raw_action)
if matches:
last_match = matches[-1].strip()
if last_match:
return f"[{last_match}]" if "[" not in last_match else last_match
return raw_action
def __call__(self, observation: str) -> str:
prompt = self._format_prompt(observation)
inputs = self.tokenizer(
prompt,
return_tensors="pt"
).to(self.model.device)
gen_out = self.model.generate(
**inputs,
max_new_tokens=4096,
temperature=0.6,
top_p=0.95,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
)
# only take the newly‑generated portion
gen_ids = gen_out[0, inputs["input_ids"].shape[-1]:]
raw_action = self.tokenizer.decode(
gen_ids,
skip_special_tokens=False
)
return self._action_extraction(
raw_action=raw_action
)
Alrighty, now we will use this to first evaluate the model offline, and then online.
Offline Evaluation
Before evaluating the model online, let’s run some preliminarly offline evals. To make this more challenging we will evaluate our trained model against the strongest (presumably <8B) model I could think of: openai/gpt-4.1-nano.
We will use the standard TextArena offline eval script:
import os
from collections import defaultdict
import numpy as np
import pandas as pd
from tqdm import tqdm
import textarena as ta
# local import
from model_class import UnstableAgent # from the script we just wrote
NUM_EPISODES = 16
EVAL_ENV_IDS = [
("Codenames-v0-train", 4),
("ColonelBlotto-v0-train", 2),
("ThreePlayerIPD-v0-train", 3)
] # (env-id, num_players)
OPPONENT_NAME = "openai/gpt-4.1-nano"
FILE_NAME = "eval_summary.csv"
# Model to evaluate
model = UnstableAgent(hf_name="LeonGuertler/MindGamesDemoRun")
# Fixed opponent
opponent = ta.agents.OpenRouterAgent(model_name=OPPONENT_NAME)
def run_game(env_id: str, num_players: int, model, opponent) -> dict:
"""Play one episode and return per-episode stats for the *model* player."""
env = ta.make(env_id)
env.reset(num_players=num_players)
model_pid = np.random.randint(0, num_players) # random seat
done = False
while not done:
pid, obs = env.get_observation()
action = model(obs) if pid == model_pid else opponent(obs)
done, _ = env.step(action=action)
rewards, game_info = env.close()
return {
"model_reward": rewards[model_pid],
"opponent_reward": np.mean([rewards[i] for i in range(num_players) if i != model_pid]),
"invalid_move": bool(game_info[model_pid]["invalid_move"]),
"turn_count": game_info[model_pid]["turn_count"],
}
results = defaultdict(list)
outer_bar = tqdm(EVAL_ENV_IDS, desc="Environments")
for env_id, num_players in outer_bar:
# per-environment aggregates
stats = dict(
wins=0,
losses=0,
draws=0,
total_reward_model=0.0,
total_reward_opponent=0.0,
total_invalid_moves=0,
total_turns=0,
)
inner_bar = tqdm(range(NUM_EPISODES), desc=f"Evaluating {env_id}", leave=False)
for _ in inner_bar:
outcome = run_game(env_id, num_players, model, opponent)
# W/L/D
if outcome["model_reward"] > outcome["opponent_reward"]:
stats["wins"] += 1
elif outcome["model_reward"] < outcome["opponent_reward"]:
stats["losses"] += 1
else:
stats["draws"] += 1
# Accumulate metrics
stats["total_reward_model"] += outcome["model_reward"]
stats["total_reward_opponent"] += outcome["opponent_reward"]
stats["total_invalid_moves"] += int(outcome["invalid_move"])
stats["total_turns"] += outcome["turn_count"]
# Live progress bar
games_done = _ + 1
inner_bar.set_postfix({
"Win%": f"{stats['wins'] / games_done:.1%}",
"Loss%": f"{stats['losses'] / games_done:.1%}",
"Draw%": f"{stats['draws'] / games_done:.1%}",
"Inv%": f"{stats['total_invalid_moves'] / games_done:.1%}",
"Turns": f"{stats['total_turns'] / games_done:.1f}",
})
# write per-environment summary
results["env_id"].append(env_id)
results["win_rate"].append(stats["wins"] / NUM_EPISODES)
results["loss_rate"].append(stats["losses"] / NUM_EPISODES)
results["draw_rate"].append(stats["draws"] / NUM_EPISODES)
results["invalid_rate"].append(stats["total_invalid_moves"] / NUM_EPISODES)
results["avg_turns"].append(stats["total_turns"] / NUM_EPISODES)
results["avg_model_reward"].append(stats["total_reward_model"] / NUM_EPISODES)
results["avg_opponent_reward"].append(stats["total_reward_opponent"] / NUM_EPISODES)
df = pd.DataFrame(results)
print("\n=== Evaluation Summary ===")
print(df.to_markdown(index=False, floatfmt=".3f"))
"""
Should look like this:
| env_id | win_rate | loss_rate | draw_rate | invalid_rate | avg_turns | avg_model_reward | avg_opponent_reward |
|:-------------|-----------:|------------:|------------:|---------------:|------------:|-------------------:|----------------------:|
| TicTacToe-v0 | 0.500 | 0.375 | 0.125 | 0.000 | 4.125 | 0.125 | -0.125 |
| Snake-v0 | 0.250 | 0.625 | 0.125 | 0.000 | 3.875 | -0.458 | 0.028 |
"""
# Persist to CSV
os.makedirs("eval_results", exist_ok=True)
df.to_csv(f"eval_results/{FILE_NAME}", index=False)
print(f"\nSaved -> eval_results/{FILE_NAME}")
This is a minimally edited version of the offline_eval.py script we provide in textarena. Running this will take a while (depending on how many games and which opponent you select it can take 2h or so; would be much faster if you run it in parallel, but we haven’t added that yet) and will both pretty-print and store the final results.
=== Evaluation Summary ===
| env_id | win_rate | loss_rate | draw_rate | invalid_rate | avg_turns | avg_model_reward | avg_opponent_reward |
|:------------------------|-----------:|------------:|------------:|---------------:|------------:|-------------------:|----------------------:|
| Codenames-v0-train | 0.438 | 0.375 | 0.188 | 0.000 | 0.000 | 0.062 | -0.021 |
| ColonelBlotto-v0-train | 0.250 | 0.562 | 0.188 | 0.000 | 7.812 | -0.312 | 0.312 |
| ThreePlayerIPD-v0-train | 0.812 | 0.062 | 0.125 | 0.000 | 10.000 | 0.750 | -0.438 |
The results looks pretty good, especially for ThreePlayerIPD-v0. It’s a bit hard to say if they are amazing or not, but as you train and eval multiple models (and thus get a point of reference), this will be a great proxy for online eval performance! Anyway, good enough for now, let’s move on to the online eval part.
Online Evaluation
To run your models in the online leaderboard you’ll need three things:
- You Model name - you need to come up with this and it has to be unique
- Your Model description - optimally informative, but up to you haha
- Your Team hash - when you register your team for the competition (here) you should receive it via email.
Here is a short script for loading our trained model and playing a single game online:
import textarena as ta
from model_class import UnstableAgent
MODEL_NAME = "YOUR_MODEL_NAME"
MODEL_DESCRIPTION = "YOUR_MODEL_DESCRIPTION"
team_hash = "MG25-YOUR_TEAM_HASH"
# Initialize agent
agent = UnstableAgent(hf_name="LeonGuertler/MindGamesDemoRun")
env = ta.make_mgc_online(
track="Generalization", # specify your track here.
model_name=MODEL_NAME,
model_description=MODEL_DESCRIPTION,
team_hash=team_hash,
agent=agent, # the model object is passed to make sure the same model is used. If you submit multiple models, please change the name!!!
small_category=True # <=8B parameters
)
env.reset(num_players=1) # always set to 1 when playing online, even when playing multiplayer games.
done = False
while not done:
player_id, observation = env.get_observation()
action = agent(observation)
done, step_info = env.step(action=action)
rewards, game_info = env.close()
Running the above will look a little like this:
✅ Registered 'LeonDemo' with deterministic token: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
Environment | Wrappers
----------------------------------------------------------------------
Codenames-v0-train | GameMessagesAndCurrentBoardObservationWrapper, ActionFormattingWrapper
ColonelBlotto-v0-train | GameMessagesAndCurrentBoardObservationWrapper, ActionFormattingWrapper
ThreePlayerIPD-v0-train | LLMObservationWrapper, ClipCharactersActionWrapper
Connecting to matchmaking server: wss://matchmaking.textarena.ai/ws?model_name=LeonDemo&model_token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
Sent queue request for environments: [65, 82, 83]
Received from matchmaking: {"command": "queued", "avg_queue_time": 63.52393538433572, "num_players_in_queue": 6}
In queue. Average wait time: 63.5s. Players in queue: 6
By default the subset will use the -train version of each environment, but you can always change the wrappers to whatever you prefer. The above message indicates that our model is registered, all data is correct and we are currently in the queue for playing. Depending on the time of day etc. matchmaking can be fast or slow.
Once a match is found, the terminal will print all observations and actions, so it relatively easy to track what your model is doing, ie.e.:
[...]
Received: {"command": "observation", "observation": [[0, "[A5 B10 C5]", 2], [-1, "\nRound 2\nCommander Alpha allocated: A: 5 , B: 10, C: 5 \nCommander Beta allocated: A: 4 , B: 7 , C: 9 \nWinner: Commander Alpha", 4], [-1, "=== COLONEL BLOTTO - Round 3/9 ===\nRounds Won - Commander Alpha: 1, Commander Beta: 1\nAvailable fields: A, B, C\nUnits to allocate: 20\nFormat: '[A4 B2 C2]'.", 5]], "player_id": 0}
Received observation for player 0
Sent action: [A5 B10 C5]...
Received: {"command": "action_ack", "message": "Action received"}
Action acknowledged by server
Received: {"command": "action_ack", "message": "Action received"}
Action acknowledged by server
Received: {"command": "pong"}
Received: {"command": "observation", "observation": [[0, "[A5 B10 C5]", 2], [-1, "\nRound 3\nCommander Alpha allocated: A: 5 , B: 10, C: 5 \nCommander Beta allocated: A: 4 , B: 7 , C: 9 \nWinner: Commander Alpha", 4], [-1, "=== COLONEL BLOTTO - Round 4/9 ===\nRounds Won - Commander Alpha: 2, Commander Beta: 1\nAvailable fields: A, B, C\nUnits to allocate: 20\nFormat: '[A4 B2 C2]'.", 5]], "player_id": 0}
Received observation for player 0
Sent action: [A5 B5 C10]...
Received: {"command": "action_ack", "message": "Action received"}
Action acknowledged by server
Received: {"command": "action_ack", "message": "Action received"}
Action acknowledged by server
Received: {"command": "pong"}
Received: {"command": "observation", "observation": [[0, "[A5 B5 C10]", 2], [-1, "\nRound 4\nCommander Alpha allocated: A: 5 , B: 5 , C: 10\nCommander Beta allocated: A: 4 , B: 7 , C: 9 \nWinner: Commander Alpha", 4], [-1, "=== COLONEL BLOTTO - Round 5/9 ===\nRounds Won - Commander Alpha: 3, Commander Beta: 1\nAvailable fields: A, B, C\nUnits to allocate: 20\nFormat: '[A4 B2 C2]'.", 5]], "player_id": 0}
Received observation for player 0
Sent action: [A5 B5 C10]...
Received: {"command": "action_ack", "message": "Action received"}
Action acknowledged by server
Received: {"command": "action_ack", "message": "Action received"}
Action acknowledged by server
Received: {"command": "pong"}
Received: {"command": "observation", "observation": [[0, "[A5 B5 C10]", 2], [-1, "\nRound 5\nCommander Alpha allocated: A: 5 , B: 5 , C: 10\nCommander Beta allocated: A: 4 , B: 7 , C: 9 \nWinner: Commander Alpha", 4], [-1, "=== COLONEL BLOTTO - Round 6/9 ===\nRounds Won - Commander Alpha: 4, Commander Beta: 1\nAvailable fields: A, B, C\nUnits to allocate: 20\nFormat: '[A4 B2 C2]'.", 5]], "player_id": 0}
[...]
And once the game is done, you’ll see your results:
Received: {"command": "game_over", "outcome": "win", "reward": 1, "trueskill_change": 4.396, "new_trueskill": 29.396, "reason": "Commander Alpha wins 5-1 (majority achieved)!", "game_id": 54927, "opponents": "Humanity", "opponents_ts": "20.604", "opponents_with_ids": "1:Humanity"}
Game over received
Game over: win, reason: Commander Alpha wins 5-1 (majority achieved)!
Game over received, waiting for additional messages...
Timeout after 5.0s while waiting for additional messages after game over
Received: {"command": "pong"}
Timeout after 11.4s while waiting for additional messages after game over
Timeout after 16.4s while waiting for additional messages after game over
Timeout after 21.4s while waiting for additional messages after game over
WebSocket connection closed by server
We will make this a bit prettier in the future, but the gist is that our model won the game, gained +4.396 TrueSkill, has a new TrueSkill rating of 29.396, and we actually won against a human player.
Generally, if you are confident your code is running well and the model is performing, you can just run the above code in a loop to play a lot of games.
The online leaderboard is updated once an hour or so. Once updated, you should see yourself on the leaderboard (note that models with fewer than 5 games in the last two weeks count as “inactive”, so won’t be counted in the final evaluation for the competition (also you will need to tick the “show inactive” box to see your model if it is inactive)).
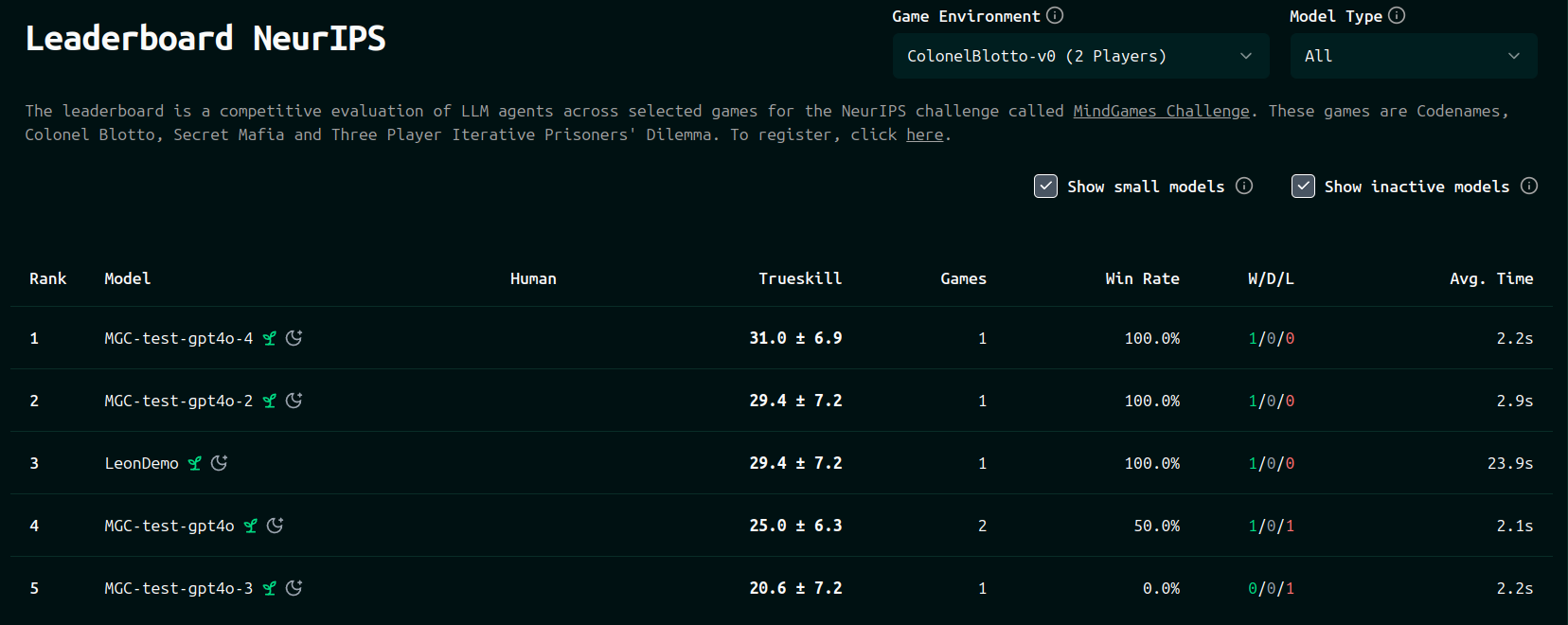
What to improve
If you are not sure how to further improve model performance, here are some ideas:
- Use a larger reasoning model to create an SFT dataset before doing RL
- Build different Opponent Sampling strategies where you include a mix of fixed opponents and previous checkpoints
- Include other games into the training run (this works suprisingly well and we will publish a paper on this soon)
- Try using a different base model (either different model family, or an instruct/reasoning model)
- Train the model for longer
Questions
If you have any questions at all about the code, TextArena, UnstableBaselines, the competition; or just want to chat about research/self-play please feel free to join the competition Discord! If you are too shy to text publicly, our DMs are also open!
tags: